Tech Stuff - DOM Page Structure and Navigation
Page Navigation and Structure
You gotta get a couple (or 50) basics clear in your mind before you start messing around with this DOM stuff. Then it's a real breeze (oh yeah!). All the examples below use javascript. If you don't know javascript you're out of luck! Observant readers may conclude that this page was written in the depth of winter when the author was nasally challenged. They are correct. Some humour, however, does not stand the test of time.
Your Document is stuck in the Window
The DOM-2 is concerned with the document and is NOT concerned with (and does not standardise) the browser window object, window attributes and capabilities are browser specific though mostly based on the old netscape specs. Here is our rough definition of the window and document:
- window: browser environment containing the status line, screen, screen dimensions etc., etc.. It acts as a container for the document object. The window is NOT defined by DOM-2 and is typically browser specific or uses de facto standards. The window is not described, except occasionally in passing, in any of these pages.
- document: defined by DOM-2 (perhaps with browser specific extensions) and is the HTML (XHTML/XML) contents of the page delivered from the server/source file and is contained within the window.
If you wrote it it's DOMable
The first key point, which may seem simple, is that the DOM provides methods to access and manipulate the HTML (XHTML/XML) of the document nothing else. Javascipt, or whatever scripting language you use, does the processing. You use the various DOM interfaces, in the W3C's quaint jargon, to access your page's HTML tags (elements) and attributes. It's that simple. Took us 6 weeks to figure this out from all that jargon!!
My Node is Cold
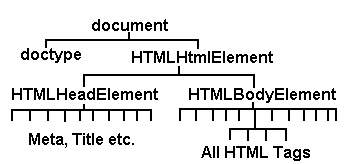
The DOM-2 defines everything, and they mean everything - including whitespace and those end-of-line thingies in a document as a node each of which may have other nodes hanging off it in a hierarchy. We can get a list of all the nodes at any given Node using the childNodes attribute. Nodes have the attribute (property) called nodeType which tells you what you can do with it, what interfaces it supports. Nodes with a nodeType of Element (an HTML element like A for anchor) will typically have further nodes and using this process you can iterate through the entire document. The following, very simplified, diagram illustrates the basic idea.
Note: The structure below assumes you do use a <!DOCTYPE declaration - well we're all well behaved HTML coders - aren't we. If you don't then doctype will not be present.
May the bird of paradise fly up your Node
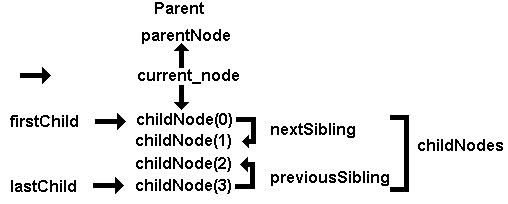
To navigate around nodes you use a mixture of attributes. In the simplified diagram below, to get to the parent node from the current node use the parentNode attribute. To get all the child nodes use the childNodes attribute. To get the first (top) child node use the firstChild attribute. To get the last child use the lastChild attribute. To move from node to node in a DOWN direction use the nextSibling attribute and in an UP direction use the previousSibling attribute.
The DOM-2 includes a quaintly named spec called the Traversal and Range Specification which provides NodeIterator, TreeWalker and NodeFilter interfaces to help in navigating a document.
Psychophrenia as a programming Technique
DOM thingies may have multiple personalities (they may support multiple interfaces). They inherit, in techno-jargon, the methods and attributes from all their ancestors - their parents and possibly their parents's parents and... you get the picture.
// this example assumes you have gotten a node
// we'll see how later. Assume, for now,
// it's an automagical process
// now get a list of all the thingies at this node
// in an array
thingylist = ournode.childNodes;
// get the first thingy
thingy = thingylist[0];
// thingy has all the node methods and attributes
if(thingy.nodeType == 1) // is it an element?
{
// now thingy has all the element methods and attributes
// if it's also in an HTML document thingy has all
// the HTMLElement methods and attributes
if(thingy.nodeName == "A")
{
// now thingy has all the HTMLAnchor methods
// and attributes as well
}
}
By progressively testing for the node capabilities in the above example our friendly (but barren) node ends up being quite rich in methods and attributes. Which method or attribute you use and from which life (node, element. HTMMLElement or anchor) is entirely up you and what you want to achieve. Mix and match anyway you want at anytime.
Where's my Node
To find any node in a document you have three choices
Give it an id in the HTML e.g. <p id='firstparagrah'>, then you can reference it using document.getElementById('firstparagraph') method of the document object. This is the best, easiest and most reliable way.
Note: The key point here is that each id is defined by the specification to be unique within a document. The W3C validator especially gets very upset if this is not true.
You can start at the root of the document and slog your way through it using the childNodes attribute of the node (using a code fragment like this) and hope you eventually find what you are looking for.
If you know the type of node you are looking for, say it's a table, you can use the document.getElementsByTagName("table") method of the document.
Where the #!***? am I?
If you are iterating your way through a document at some point you got to try and figure where you are. And what kind of nodes you are looking at so that you can use the allowable methods and attributes, or apply the appropriate interface in the W3C jargon to achieve your goal. If, after all that effort, you can remember what it was. There are two attributes (and only two) that can help you here.
nodeType attribute. The most important 'cos it tells you what type of 'thingy' you've got and hence what type of methods and attributes it has (full list).
// start from the document root
nodelist = document.childNodes;
// find out if we got anything interesting
for(i = 0; i < nodelist.length; i++)
{
// test for an element else ignore
if(nodelist[i].nodeType == 1)
{
// if no child nodes we ignore the node
if(nodelist[i].hasChildNodes() == true)
{
// else get 'em
newnodelist = nodelist[i].childNodes;
// do something or keep on going
}
}
}
nodeName attribute. This is most reliable way to tell what element you got (it's true cos the W3C says so). So now you got to test for the HTML element you are looking for which will finally tell you exactly what attributes and methods you can use on your thingy.
// start from the document root
nodelist = document.childNodes;
// find out if we got anything interesting
for(i = 0; i < nodelist.length; i++)
{
// test for an element else ignore
if(nodelist[i].nodeType == 1)
{
// if no child nodes we ignore it
if(nodelist[i].hasChildNodes() == true)
{
// if it's a table element we want it
if(nodelist[i].nodeName == "TABLE")
{
// we get all 'em children
tablenodelist = nodelist[i].childNodes;
// look for something with id="the-one"
for (k = 0; k < tablenodelist.length; k++)
{
if(tablenodelist[k].id == "this-one")
{
// gottcha
}
}
}
}
}
}
Now smart folks will have spotted the fact that if we know the id of the element and we know it's in a table them we could have done this instead:
// get the id we are looking for
gotcha = document.getElementById("this-one");
// now find its table parent using a local function
table = getaparent(gotcha,"table");
// now do something useful
function getaparent(node,name){
// iterative function to get parent
// function will loop and fail if not properly
// structured - test for HTMLBodyElement nodeName = "body"
// to give error
if(node.parentnode.nodeName == name)
{
return node.parentnode; // return the node
}else{
getaparent(node.parentnode,name); // iterate
}
}
Let's get under the hood and pull it to bits
It you are into masochism you can play with this stuff and deconstruct an HTML page. You can explore a page here using our early programming experiments OR by far the best tool we've come across is Mozilla's DOM Inspector a stand-alone page inspector/explorer which ships as standard with Mozilla. Update: Almost all the browsers now ship with some kind of DOM explorer - usually under 'Developer Tools'.
Problems, comments, suggestions, corrections (including broken links) or something to add? Please take the time from a busy life to 'mail us' (at top of screen), the webmaster (below) or info-support at zytrax. You will have a warm inner glow for the rest of the day.