Definition - in our own idiosyncratic way - of a number of terms used in the audio/video world. As is always the case with terminology different terms are sometimes used to describe the same concepts. In some cases the meanings are subtly different. Sometimes the user of the term is aware of the difference and has used it in the correct context. In many cases blissful ignorance reigns supreme. We try and note (pun) where we know (not often) the subtleties.
| 1st Harmonic |
A.k.a Fundamental. |
| AIFF |
See AIFF Format. Audio Interchange File Format. Widely used on Apple systems and generally defines a lossless format (roughly Apples' equivalent of WAV). |
| AAC |
See AAC File Format. Full name MPEG-4 Advanced Audio Codec. Lossy audio compression algorithm. |
| ADC |
Analog to Digital Converter. A semi-conductor device which samples an incoming analog signal at a particular rate (the sample-rate) and converts it to a given number of bits (the sample-size (bit-depth). ADCs come in a variety of specifications from 4 to 32 bits and with a wide range of sample-rates. Conversion from digital to analog uses a DAC. |
| ADSR Envelope |
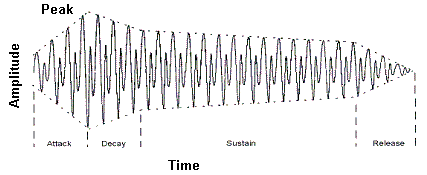
A.k.a. Amplitude Envelope. The Amplitude envelope of a note is the change in amplitude (while the frequency remains constant) over time and is composed of the attack, decay, sustain and release times. The ADSR envelope is determined by the characteristics of the device that is generating the note. So a piano will have a very different ADSR from a saxophone etc.. The ADSR (Amplitude) envelope together with the harmonics and the overtones give every instrument is unique timbre or sound. An example of an ADSR is shown below:
 |
| Amplitude |
The power of a signal. In the time-domain it defines the distance of a signal from a zero base (can be both positive or negative) at a particular time. When sound is digitized the individual samples from the ADC (Analog to Digital Converter) represent the value of the amplitude (accuracy of the measurement is determined by the sample size) of the analog wave form at one sample period (the sample rate). |
| Amplitude Envelope |
A.k.a. ADSR (Amplitude) envelope. |
| Attack time |
The term attack is used in two senses. First generically to indicate the rise in amplitude of any frequency from a zero base. Second as a one component of the ADSR (Amplitude) envelope being the time taken to rise from zero amplitude to the peak and is determined by the characteristics of the device that is generating the note. So a piano will have a very different attack time from a saxophone. The ADSR (Amplitude) envelope together with the harmonics and the overtones give every instrument is unique timbre or sound. |
| Bit Depth |
a.k.a. Sample size. |
| Bit Rate |
Expressed in bits per second or K bits per second and abbreviated either as bps or bit/s. Term used to describe the amount of compression that will occur when using a lossy algorithm to encode an audio file (not to be confused with the sampling bit rate). As an example the MP3 bit rate varies from 96K to 320K bits per second. The lower the bit rate the more compression is applied (generally resulting in lower quality sound) but a smaller the file. Conversely the higher the bit rate the higher the quality of the sound and the bigger the file. Most MP3 systems use 128K bits per second which results in what is sometimes called (FM) radio quality. Ogg Vorbis bit rates vary from 45K to 500K. |
| Butterfly Stereo |
Technigue for combining 2 or more stereo channels into a single mono channel. See Stereo. |
| CODEC |
Generic term for any audio/video COder and DECoder. The COder will handle the conversion of the digital stream coming from the ADC (Analog to Digital Converter) into a specific file format such as MP3 or Ogg Vorbis and the DECoder supplies the bit/byte stream to the DAC (Digital to Analog Converter) to create some real world noise. In some cases the CODEC will also transcode (or convert) from one audio format to another typically - but not always - this is dome by normalizing the input audio data to PCM format before converting into another format. |
| DAC |
Digital to Analog Converter. A semi-conductor device which takes a digital input value and converts it to an analog waveform at a given rate (the sample-rate). DACs come in many shapes and sizes and will handle a variety of bits (the sample-size (bit-depth) and sample-rates. Conversion from analog to digital uses an ADC. |
| Decade |
The term decade in the acoustic world implies frequency ratios of 10:1 between decades and is most commonly used in filtering and equalization systems, for example, the classic Bass, Mid and Treble controls. The audio frequency range (20 Hz to 20 KHz) are covered by 3 decades, being Bass: 20Hz - 200 Hz, Mid: 200Hz - 2 KHz and Treble: 2KHz to 20 KHz. Where only Bass and Treble controls are provided they typically cover Bass + Mid as one and the Treble decade: See also Octave. |
| Decay time |
The decay time of a note is one component of the ADSR (Amplitude) envelope being the time taken to fall from the peak (at the end of the Attack to the sustain time and is determined by the characteristics of the device that is generating the note. So a piano will have a very different decay time from a saxophone. The ADSR (Amplitude) envelope together with the harmonics and the overtones give every instrument is unique timbre or sound. |
| Decibel |
Widely used unit of measurement being 1/10 of a bel and normally written as dB. The decibel is simply the logarithmic (base 10) ratio of two values of the same type and as such is dimension-less. Typically one of values being compared will be a reference value. In order to indicate the types being compared it will normally have a suffix of one or more characters. In many cases the meaning is implied within a context thus in acoustic systems dB is normally taken to mean dB(SPL) - Sound Pressure Level - to determine the effect on the human ear as one measure of 'loudness'. Other values that are used in acoustic systems are dB(A), dB(B) or dB(C) which means that a weighting factor has been applied (A, B or C respectively) to account for the sensitivity of human hearing. dBu is a electrical measure (voltage relative to 0.775V) but is sometimes used when describing the scales used with a VU meter or a PPM since historically these instruments used electrical outputs to make the analog meter needles move. dBFS (Full Scale) is used with systems that have a maximum output value and is normally defined relative to the value when clipping occurs (normally 0db(SPL)). For most practical purposes 0db (or 0dB(SPL) = 0dbFS. |
| Dissonant |
|
| Dither |
Dithering is required when a signal recorded at one level of accuracy is played back at a lower level of accuracy and involves adding random noise to the signal to avoid the regular (repeating) distortion that would otherwise occur if a consistent algorithm was used. The human ear apparently is happier with random noise than with a regular distortion. Assume we have recorded some audio using a 24 bit sample size. We now want to create an audio CD which only has a 16 bit sample size. If we apply a regular algorithm, say, truncation or rounding up or down, then predictable distortion will occur. Instead, an essentially random number is used (and given fancy titles such as Rectangular Probability Density Function) which results in random noise that is more pleasing to the listener (or should that be less unpleasant). |
| Dry |
Generic term for any unprocessed audio signal or that part of an audio signal which is not processed during a DSP operation. See also wet. |
| DSP |
Digital Signal Processing (DSP). Generic term for any process that manipulates a signal, such as a time domain waveform. Thus, a function that creates or plays back a compressed sound file, for example, an MP3 file, could be called a DSP or DSP function. Also widely used to describe a specialized microprocessor optimized for handling signal processing and typically with high-speed floating point arithmetic capabilities since it will frequently execute complex FFT operations. |
| Dynamic Range |
Term used to describe the range of values from the highest to the lowest, measured in dB(SPL), supported by an audio system. In digital audio systems this is determined by the sample size and calculated using the formula 1.76 + 6.02 * sample rate and is typically shortened to a 'rule of thumb' as 6 dB(SPL) per bit. A CD (16 bit sample size) has a dynamic range of 96 dB(SPL). A DVD (using a 24 bit sample size) has a dynamic range of 144 dB(SPL). We poor humans have a dynamic range of 140 dB(SPL). |
| Equalization (EQ) |
An equalizer (or the process of equalization) allows for a relative boosting (or suppression/attenuation) of certain frequencies (bands of frequencies) between the source of the audio material, such as a microphone or recorded material, and its output, such as a loudspeaker or a recording system. While the term is frequently used when modifying recorded material, equalizers are also routinely used in PA (Public Address) systems and performance locations or any other amplified environment to get the right balance of sound. Equalizers come in a bewildering array of types from simple bass, treble controls to 31 band (1/3 octave) or even larger. Futher Explanation |
| FFT |
Fast Fourier Transform. Far too complex an idea for our modest brains. Essentially FFT is a high-performance variant of the Discrete Forier Transform (DFT) an algorithm that allows a waveform in the time-domain to be transformed (decomposed) into the amplitude and phase of its component frequencies in the frequency-domain. Conversely you can create a time-domain waveform given the frequencies that you want to be present (Inverse FFT). The FFT is used when the number of input samples is always a power of 2, for example, 256, 512, 2048 etc.. This has the effect of sppeding up calculation of the DFT by a factor of 100 at 1024 input samples. If you are insatiably curious read this almost - almost - understandable description of FFT or our FFT Notes. |
| Filter |
Generic term applied to a process of selecting certain frequencies or bands of frequencies. The term has to be qualified to give it meaning, for example, a low pass filter, cut off filter etc. In the analog world filtering is done with circuits - in the digital world algorithms are applied to the frequenecies obtained from an FFT of the sound samples. |
| FIR |
A FIR (Finite Impulse Response). Contrast with IIR equalizers. |
| FLAC |
Free Lossless Audio Codec. See FLAC Formats. |
| Frequency |
The rate at which a signal oscillates - cycles - from zero to its highest point, passes through zero to its lowest point and then returns to zero. The oscillation or cycling may repeat indefinitely. Frequencies are measured in cycles per second (cps) a.k.a. Hertz (abbreviation Hz). Thus a signal with a frequency of 800 cycles (or oscillations) per second would more commonly be referred to as being 800 Hz. |
| Frequency Domain |
When sound is converted via a transducer the resulting output is a Time Domain waveform which is the sum of all the frequencies over time. To look at individual frequencies the time domain must be converted to the frequency domain using an FFT algorithm. Additional Explation. |
| Fundamental (Tone/Frequency) |
A.k.a note when applied to musical instruments. A.k.a 1st Harmonic is the base of fundamental frequency associated with a signal or sound. It will have additional harmonics and perhaps Overtones. |
| Haas Effect |
The Haas effect (after Helmut Haas) simply says that if the same sound arrives at the human ear with a separation above 40 milliseconds then the listener will perceive it as coming from a different source - below 30 - 40 milliseconds the listener will perceive it as coming from the same source. There seems to be no real consensus over exactly where the break-point between same and different source occurs, with some papers quoting 50 milliseconds others 40 milliseconds others even lower. The Haas effect can be used when creating stereo from mono recording or when creating surround-sound or complex sound effects to emulate various physical locations e.g. a concert hall. |
| Harmonic |
When a musical instrument (that includes the human voice) produces a note, say A4, this is called the fundamental tone (a.k.a fundamental frequency or pitch). The note, based on the characteristics of the instrument, has an ADSR (Amplitude) Envelope and produces a series of harmonics (each of which also has an ADSR) which are integer multiples of the original frequency (it also produces overtones which may be different). Just to confuse things a tad further the fundamental tone (or frequency) is counted as the 1st harmonic. Thus in our example the fundamental tone (A4) has a frequency of 440Hz (a.k.a. the 1st harmonic) with a 2nd harmonic at 2 x 440 = 880Hz, a 3rd harmonic at 3 x 440Hz = 1320Hz (1.32 KHz) and so on essentially forever (but each - generally - getting successively weaker). The strength (amplitude) of each harmonic relative to the fundamental (and in some cases even its presence) is determined by the instrument design and gives the instrument is unique sound or timbre. While we all know that a piano and a saxophone playing the same note, say A4, sound very different that difference is explained by the number and strength of each harmonic, the number and strength of the overtones (and whether they coincide or not with the harmonics) and the ADSR. Extended explanation. |
| Hertz |
Term used to describe frequency and defines the number of cycles (or oscillations) per second. Abbreviation Hz. Thus, 1 Hz is one cycle per second, 1,000 cycles per second is 1,000 Hz or 1 KHz and 1,000,000 cycles per second is 1,000,000 Hz or 1 GHz. Named after Heinreich Hertz. |
| HRTF |
Head Related Transfer Function. A Psychoacoustic technique that mathematically describes how sound is treated when it reaches the ear and can be used to artificially create unique (example surround-sound) effects. |
| IIR |
An IIR (Infinite Impulse Response). Contrast with FIR equalizers. |
| Lossless |
A Lossless algorithm (or CODEC) is one which does not discard data from the source material. Examples of lossless CODECs are WAV and FLAC (which also compresses) |
| Lossy |
A Lossy A/V compression algorithm (or CODEC) is one which discards data from the source material. It achieves high levels of reproduction quality based on the use of some data compression techniques but especially psychoacoustic techniques to ensure that the listener's perception of the resulting audio stream is as close to the original as possible (with respect to the compression requirement). Algorithms (CODECs) which use this approach are sometimes called perceptual encoders. |
| Loud/Loudness |
One of those things that appear to be simple but is fiendishly complicated. We all know when something is load or not but turns out to be devilishly difficult to define since it is a subjective measure. It is normally directly related to the dB(SPL) but we have more sensitivity to certain sound ranges as defined by the Fletcher-Munson (and ISO) curves. Further Explanation |
| Loudspeaker |
A single loudspeaker design cannot handle the full range of human sound (20 Hz to 20 KHz) due to physical constraints. To solve this problem what is called a loudspeaker has (at least) two separate loudspeakers. One for the high frequencies (normally 2 KHz to 20 KHz) called a tweeter. One for the lower frequencies (20 Hz - 2 KHz) called a woofer. When sound arrives at the loudspeaker it is filtered (separated) into the two (or more) frequency ranges. In some high end systems a mid-range (a.k.a. squawker) speaker handles the range 300 Hz to 2/3 Khz (roughly corresponding to the 2nd decade) with the woofer handling the 1st decade and the tweeter handing the 3rd decade frequencies. |
| Low-Pass Filter |
a.k.a cut-off filter. Term applied to a filter which removes or attenuates frequencies above the filter circuit design theshold. In the digital world the filter threshold is normally defined by a user supplied variable. As an example both the recording and playback mechanisms of a CD have a low-pass filter with a threshold of 20 KHz to eliminate frequencies above this range. |
| Microphone |
A device for converting sound into an electrical signal that may be recorded, sampled (digitized) or directly used to drive a loudspeaker. Microphones may be made from a number of materials and typically have some form of directionality. The generic term for a microphone is a transducer. |
| Mid-Range |
A single loudspeaker design cannot easily handle the full range of human sound (20 Hz to 20 KHz) due to physical constraints. To solve this problem what is called a loudspeaker has (at least) two separate loudspeakers. One for the high frequencies (normally 2 KHz to 20 KHz) called a tweeter. One for the lower frequencies (20 Hz - 2 KHz) called a woofer. In some high end systems a third speaker known as a mid-range (a.k.a. squawker) speaker handles the range 300 Hz to 2/3 Khz (roughly corresponding to the 2nd descade) with the woofer handling the 1st decade frequencies. When sound arrives at the loudspeaker it is fitered (separated) into the various frequency ranges. Where a mid-range speaker is present there will norammly be 3 volume controls (Bass, Mid, Treble). When sound frequency ranges are measured in decades (as opposed to octaves) the mid-range speaker reproduces the 2nd decade. |
| Mono |
Monophonic Sound - more commonly known as mono - is defined as being a system using a single recording channel and a single playback channel. Whereas Stereophonic (a.k.a. stereo) uses (at least) two recording channels and two playback channels. When mastering older, mono, recordings a variety of techniques may be used to create a stereo effect from simple replication (with or without Haas effect) to splitting high and low frequencies. |
| MP3 |
See MP3 File Format. Full name MPEG-1/2 Audio Layer 3. MPEG standards are defined by the ITU. |
| MPEG |
Moving Pictures Experts Group is a workgroup of ISO (International Standards Organization) - or as their web says International Organization for Standardization - must have taken years to get that agreed)/IEC (International Electrotechnical Commission) and is responsible for numerous standards relating to audio and video. Officially ISO/IEC JTC/SC29/WG11. The MPEG official web site appears to be here. Since these guys charge for specs you would think they would at least be able to afford their own web site. |
| Note |
A musical note is a sound (a.k.a fundamental tone or fundamental frequency or even 1st harmonic) with a specific frequency (see musical notes by frequency). However when a note is produced by a musical instrument then it is comprised of the note's fundamental frequency, harmonics, overtones and has an ADSR (Amplitude) envelope, the totality of which give it a distinctive sound or timbre. The type and design of the instrument (including the human voice) determine the characteristics of the harmonics, overtones and ADSR. Thus in some instruments certain harmonics may be missing completely or the overtones may be significantly out of phase. |
| Octave |
The term Octave in the acoustic world defines any system whose frequency ratios are 2:1. It has two specific uses. A musical Octave goes from the note C to B and is based on a base (or tuning) frequency of A4 = 440 Hz. The term is also used in equalization systems where it is typically based on a standard center freguency (defined by ISO/ANSI etc) of 1000 Hz (1 KHz). Around 10 Octaves are needed to cover the range of human hearing. See also Decade. |
| Overtone |
An overtone is defined as a non-integer multiple of the fundamental frequency (whereas a harmonic is defined as a integer multiple of the fundamental frequency). For certain instruments, especially stringed instruments (such as a piano, guitar, violin etc.) or long thin instruments such as a trombone, the first few overtones largely coincide with the harmonics. When counting overtones we always exclude the fundamental frequency so even when they coincide with the harmonic they will be numbered one less, thus the 3rd harmonic would be the 2nd overtone etc. The terms Harmonic and Overtone are sometimes used synonymously. This can be very confusing and is always imprecise for two reasons. Numbering of overtones is never the same as the numbering of harmonics (q.v.) and while harmonics and overtones can and do coincide at the lower end in some instrument types this is not always the case and in the case of the higher harmonics and overtones is almost never the case. |
| PCM |
PCM (Pulse Coded Modulation) is a digital representation of a analog audio signal stream. The PCM data is normally stored internally within an application or written to a file system in which case it will have a file format wrapper. The term LPCM (Linear Pulse Coded Modulation) is technically more correct when stored in a processing system of some sort (a PC) and is frequently used interchangeably with PCM. In a PCM/LPCM system the raw audio data is obtained from the Analog to Digital Converter (ADC) at a particular sample rate (MPEG and most other systems support 16, 22.05, 24, 32, 44.1, 48KHz sample rates with 96 kHz and even 192 kHz becoming available) and a sample size (typically 8, 12, 16, 20 and 24 bits). As illustrative examples: A CD uses LPCM at a sample rate of 44.1KHz and a sample size of 16 bits, a DVD samples at 48Khz with a sample size of 16 bits with high end players using 24 bits. WAV and AIFF format files store the audio data in raw PCM/LPCM format.
|
| Pitch |
The sound (frequency) of a note. |
| Psychoacoustics |
Psychoacoustics are concerned with how the listener perceives the arriving sound. Psychoacoustic techniques are used extensively in lossy CODECs (and as such these are sometimes called perceptual encoders) since they result in significant reductions in data volumes because they can discard data which is known to have little effect on the listener (constrasted with classic data compresion techniques which have no knowledge of the type of data being represented). The Haas Effect and HRTF are examples of Psychoacoustic techniques. |
| PPM |
PPM (Peak Programme Meter) defines a device for measuring audio data in which peaks are captured. This contrasts with a VU-Meter where peaks are typically not captured. The PPM tends to be used more in Europe whereas the VU-Meter tends to be used in the US. The scale of a PPM is typically a dimension-less numeric range (values differ from country to country) which has an indirect relationship with dB(SPL). The BBC PPM (where the device was originally developed) typically provided 4 channels in stereo systems where the A channel was the Left (or Red), B the Right (or Green), S the sum (A + B -3 or 6dB) and M the difference (A-B - 3 or 6 dB). These definitions apply to the original analog devices. Modern software when providing metering services can capture and process any event so the differences between PPM and VU-Meter may tend to become blurred and arguably even irrelevant - for other than those seriously afflicted with nostalgia. |
| Quantization |
The process of measurement or assigning something a specific value or qualtity. In acoustics, quantization refers to the process of sampling electrical signals from a microphone ( a transducer) using an Analog to Digital Convertor (ADC). The measuring or quantization process always incurs a quantization error. |
| Quantization error |
When an analog signal, which is a constantly changing value, is coverted to a digital sample using an Analog to Digital Convertor (ADC) an error is always introduced as a by-product of this process. In essence the digital sample is an approximation of the analog signal. The error may occur due to truncation, generally due to the sample size (a 24 bit ADC will yield a lower error than a 16 bit ADC) or rounding, generally due to the sampling rate (sampling at a higher frequency will have a lower error). Dithering algorithms are sometimes used to compensate for the quantization error. |
| Release time |
The release time is one component of the ADSR (Amplitude) envelope being the time the note (frequency) takes to return to zero amplitude when it is stopped. So a piano will have a very different release time (with or without using the sustain pedal) from a saxophone. The ADSR (Amplitude) envelope together with the harmonics and the overtones give every instrument is unique timbre or sound. |
| Renard Numbers |
Renard numbers are used to create the Preferred Frequencies defined in ISO R 266-1997 using tables R5, R10, R20, R40 and R80 of ISO 3. The tables are based on multiples, respectively, of the 5th, 10th, 20th, 40 and 80th root of 10. |
| RMS |
RMS (Root Mean Square a.k.a. Quadratic Mean)) is a mathematical method of measuring a value that changes over time. It is calculated as: square root ( sum of the squares of all the values/number of values). It provides a better measure of aucoustic content than the simple mean (average) since the efffect of higher values is accentuated and is used in variety of acoustic metering/measuring systems including VU-Meters. |
| Sample Rate |
Defines the rate at which analog audio is sampled and then converted to digital format using an ADC (Analog to Digital Converter). Sampling (Nyquist) theory determines the sampling rate should be twice the highest frequency of the material being sampled. Thus CD music is recorded in the range of human hearing which covers a frequency range of 20Hz to 20KHz and is typically sampled at 44.1KHz (just over twice the maximum required frequency) when converted to a digital format. Sample rates covered by various standards include 8K, 16K, 22.05K, 24K, 32K, 44.1K and 48K (with 96K and 192K becoming available). DVD's typically sample at 48KHz. The lower the sample rate the lower the frequency range of the captured sound material. Thus if a CD is sampled at a rate of 22.05K the frequencies above ~11KHz will be lost. Depending on the material involved this may or may not lead to a loss of quality. Conversely there is little point in sampling a CD at 48KHz or 96K since no additional material or accuracy will be obtained since it was recorded at a sample rate of 44.1KHz. |
| Sample Size |
a.k.a. Bit-depth. Defines the number of significant bits in each sample arriving from the ADC (Analog to Digital Converter). The value sampled is the amplitude of the waveform in volts. Typical sample sizes are 8 bits, 12 bits, 16 bits (most common today), 20 bits and 24 bits. The bigger the sample size the more accurate the value obtained (the smaller the quantization error) and hence the higher the quality of the resulting audio. There is, however, little point in using a sample size of, say, 24 bits and then running it through a lossy compression CODEC with a resulting bit rate of 8kbit/s! See also (PCM(LPCM). CDs use a 16 bit sample size, DVDs 16, 20 or 24. |
| Squawker |
An alias for the mid-range speaker typically handling the range 300 Hz to 2 - 3 Khz (roughly corresponding to the 2nd decade). |
| Stereo |
Stereophonic Sound is defined as being an audio system using (at least) two recording channels and two playback channels. Whereas monophonic (a.k.a. mono) uses a single recording channel. In a stereo system the two channels are typically known as the Left (or A or first or Red) channel and the Right (or B or second or Green) channel. The term joint stereo refers to various techniques used in lossy audio compression techniques (such as MP3, Ogg Vorbis or AAC) to reduce the data volume. Butterfly stereo is a technique used to combine two stereo channels into a single (mono) channel and takes the peak (postive) amplitude from one channel (typically the left) and the trough (negative) from the other (right) channel. Mean Stereo is another technique for combining two stereo channels into a single (mono) chnannel which takes the arithmetic mean of the amplitude of both channels. |
| Sustain time |
The sustain time is one component of the ADSR (Amplitude) envelope being the time the note (frequency) remains at a relatively steady (or flat'ish) amplitude before beginning the release time. So a piano will have a very different sustain time from a saxophone. The ADSR (Amplitude) envelope together with the harmonics and the overtones give every instrument is unique timbre or sound. |
| Time Domain |
When sound (a signal) is converted via a transducer the resulting output is captured as a time domain waveform which is the sum of all the frequencies present over time. When it is desired to look at individual frequencies, the time domain vaweform must be converted (transformed) to the frequency-domain using a Discrete Fourier Transform (DFT) or which the most common implementation is the Fast Fourier Transform (FFT) algorithm. Additional Explanation. |
| Timbre |
The timbre of an instrument is the overall effect perceived by a listener. Thus the timbre (the sound or sound characteristic) of a piano and a saxophone playing the same note are perceived to be very different. The timbre is created by the combination of the fundamental tone and the instrument harmonics, overtones and the ADSR Envelope. |
| Transcode |
Fancy name for converting a file in one format to another, for example, a file may be transcoded (converted) from MP3 to AAC format (M4A) to let it play on an iPod. |
| Transducer |
Generic term for any device that converts one form of energy into another. In acoustics both microphones (sound to electricity) and loadspeakers (electricity to sound) are transducers. |
| A single loudspeaker design cannot easily handle the full range of human sound (20 Hz to 20 KHz) due to physical constraints. To solve this problem what is called a loudspeaker has (at least) two separate loudspeakers. One for the high frequencies (normally 2 KHz to 20 KHz) called a tweeter. One for the lower frequencies (20 Hz - 2 KHz) called a woofer. When sound arrives at the loudspeaker it is filtered (separated) into the two (or more) frequency ranges. Because it deals with higher frequencies the tweeter is named for the high pitched (high frequency) tweet'ish sounds made by birds. The treble volume control on a sound system controls the tweeter. When sound frequency ranges are measured in decades (as opposed to octaves) the tweeter reproduces the 3rd decade. In some high end systems a mid-range (a.k.a. squawker) speaker handles the range 300 Hz to 2/3 Khz (roughly corresponding to the 2nd descade) with the woofer handling the 1st decade frequencies. |
| VU-Meter |
A VU (Volume Unit) meter measures the output signal of an audio system and is normally used to indicate loudness and typically had a dimension-less scale value of +3 to -20 (which has an indirect and vague relationship with dB(SPL). The original VU meters were analog devices with needle dials and, due to their circuit design, did not capture signal peak values (contrast with a PPM). VU-Meters were typically used in the US whereas PPM were used in Europe. Modern software used to implement VU meters can be programmed in a variety of ways to capture peaks, display dB(SPL) scale and use summed or RMS algorithms. The tern VU meter is increasingly being used to describe any metering software device that shows loudness. |
| WAV |
See WAV Format. Full name Waveform Audio Format (not Windows Audio Visual). |
| Wet |
Generic term for any processed audio signal or that part of an audio signal which is processed during a DSP operation. See also dry. |
| Woofer |
A single loudspeaker design cannot easily handle the full range of human sound (20 Hz to 20 KHz) due to physical constraints. To solve this problem what is called a loudspeaker has (at least) two separate loudspeakers. One for the high frequencies (normally 2 KHz to 20 KHz) called a tweeter. One for the lower frequencies (20 Hz - 2 KHz) called a woofer. When sound arrives at the loudspeaker it is filtered (separated) into the two (or more) frequency ranges. Because it deals with lower frequencies the woofer is named for the low pitched (low frequency) growl or woof sounds made by dogs. The Bass volume control on a sound system typically controls the woofer. When sound frequency ranges are measured in decades (as opposed to octaves) the woofer normally reproduces the 1st and 2nd decade. In some high end systems a subwoofer has been introduced to handle the very low range 20 Hz to 100/120 Hz (corresponding roughly to the 1st decade) yet others add a mid-range (a.k.a. squawker) speaker to handle the range 300 Hz to 2/3 Khz (roughly corresponding to the 2nd descade) while the woofer handles only the 1st decade frequencies. |
| Xiph |
The Xiph.org Foundation is a non-profit organization dedicated to providing open source, patent/royalty-free audio/video standards including Theora (video compression standard), speex (a variable bit rate CODEC for low-latency VoIP) and FLAC (a compressed, lossless audio standard). |